
Table of contents

How to find and eliminate duplicate site pages?
22 April 2022
Reading time: 7 minutes
Duplication of content on the site - full or partial - leads to a number of problems. It becomes more difficult for search engines to index and rank pages, behavioral factors worsen, and there is a risk of falling under filters. Therefore, duplicates must be constantly monitored and removed in time.

Types of takes
Not all takes are the same. Usually they are divided into two types - complete and partial. Let's consider each of them in more detail.
Full takes

These are pages that have exactly the same content but different urls. These duplicates include:
- pages with www and without www;
- website version on http and https protocols;
- url with and without trailing slash;
- technical duplicates - index.php, index.html, default.aspx and others;
- addresses with utm tags to track attendance statistics;
- url with tags for the referral program (in which the user receives bonuses if he brings new clients);
- duplicates due to errors in the hierarchy - typical for online stores when product cards are repeated in different sections;
- Duplicates resulting from a misconfigured 404 page.
Incomplete takes
This is a partial copy of information on pages with different addresses. For example:
- repetitions of categorical texts on catalog urls generated by applying filters or pagination;
- duplication of characteristics in cards of similar products;
- customer reviews placed in product cards and on a separate page;
- Copied content blocks on service pages (such as “About Us”, “Our Benefits”, etc.).
Why might they occur?
- Automatic generation from CMS.
The content management system can create technical duplicates of category pages or product cards.
- Structure changes.
When changing the urls of sections of the site, it is necessary to correctly register 301 redirects. Otherwise, the page will open at the new and the old address at the same time.
- Incorrect work of 404 pages.
Due to a technical error, incorrectly typed urls may copy content from existing pages and end up in the index.
- Initially incorrect structure.
Some cards can be loaded into different sections and opened under different addresses.
- Unclosed mirrors.
For search engines, https://www.example.com and http://example.com are two separate resources, although their content is identical. Such duplicates must be “glued together” with 301 redirects even before the main launch of the site.
How dangerous for the site?
- Indexing difficulty.
Search engines have a so-called crawl budget - a limit on the number of indexed urls per day. If the robots process a lot of duplicates, it becomes more difficult for the correct pages to get into the index.
- Problems with determining relevance.
Search engines have a hard time deciding which of two pages with identical content to consider relevant to a user query. Because of this, the site ranks worse on average in the SERP.
- Incorrect link weight distribution.
Users can externally link to a duplicate url instead of the main page.
- The threat of sanctions.
Due to the large amount of non-original content, search engines can send the site under filters and exclude it from the search results.
How to find?
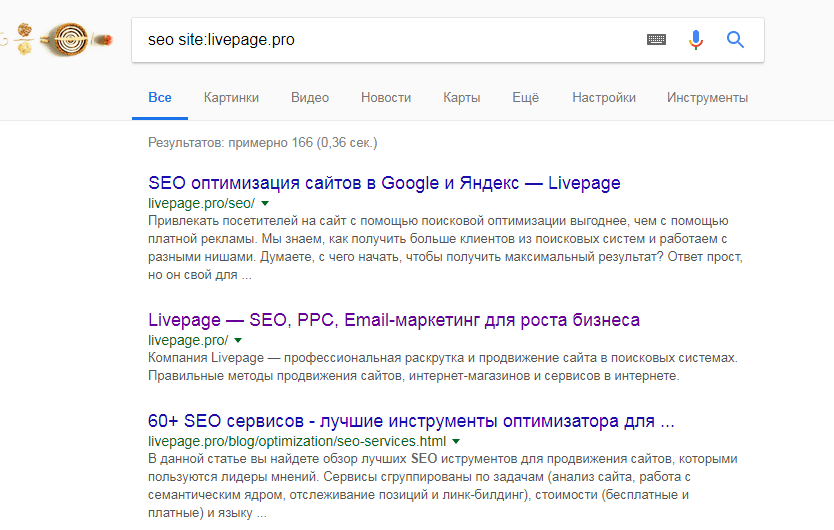
There are many ways to detect duplicates.
- With the help of crawlers such as Netpeak Spider, Screaming Frog, Megaindex. The program scans the entire site and marks the duplicates found.
- If the resource is small, pages can be checked manually using a special operator. In the Google or Yandex search bar, you need to enter the site: command and the site address. A list of all urls with titles and descriptions will appear in the output.
- You can add a piece of text before the operator from the previous paragraph. Then the search results will display all the pages that contain this snippet.
- Via advanced Google search. If you enter the address of a specific page, you can see its duplicates with similar addresses.
- With webmaster panels. In Yandex.Webmaster, you need to go to the "Indexing" and "Titles and Descriptions" sections, and in the Google Search Console - "Coverage".
- You can find duplicate texts both on external sources and within the site using anti-plagiarism check from text.ru or Content Watch.
How to fix

The way to eliminate a duplicate depends on its type and the reason for its appearance.
- Disable via directive in robots.txt.
Suitable for bulk duplications, such as filters in a catalog. To exclude all duplicate pages from the index, you need to write a rule for the common part of their addresses (Disallow: *filter*). At the same time, it is important to ensure that landing urls are not banned.
- 301 redirect
With its help, mirrors are glued together or the site structure is changed. Redirects are usually set via the .htaccess file.
- Rel=”canonical”.
The line with this tag in the html code of the page tells Googlebot the address of the canonical, that is, the main page. This way you can close addresses with utm tags, paginations or individual pages/sections from indexing.
- Meta name="robots" tag.
Direct instructions for the robot, written in html. Suitable for print pages or technical duplicates.